Transcription
Assistant Project @ E-Scripts
This is a Java Application connected with the
Emergent Transcriptions System, which represents an attempt at streamlining the
process of “unearthing” the largely-untapped goldmine of historical knowledge
contained in handwritten manuscripts stored in the archives all around the
world. The basic idea is to make it
possible for scholars to easily access the historical information contained in
ancient manuscripts by instituting a virtuous cycle of automatically-accruing
and ever-improving transcriptions of these ancient records.
Please, read the paper entitled Making
History: an Emergent System for the Systematic Accrual of Transcriptions of
Historic Manuscripts for more detailed information.
The Transcription
Assistant v.0.2
The
Transcription Assistant™ (TA) is an open-source Java application that runs on
an end-user machine through the Java Virtual Machine supported by the Java
Application Interface. With the TA,
scholars will be able to create a project for each paper or research
topic. A project will include several
manuscript pages from a variety of collections that together contribute to the
development of an historical paper on a specific subject matter.
For each manuscript used in a project, after an XPG image
or an MML transcription is downloaded, the transcriber will use our Transcription Assistant to transcribe all or part of the
document. Once the transcription is
done, transcribers are invited to submit their transcriptions back to the
archive so they can be made available to other transcribers. Specific incentives are used to make this
sharing inviting to the user.
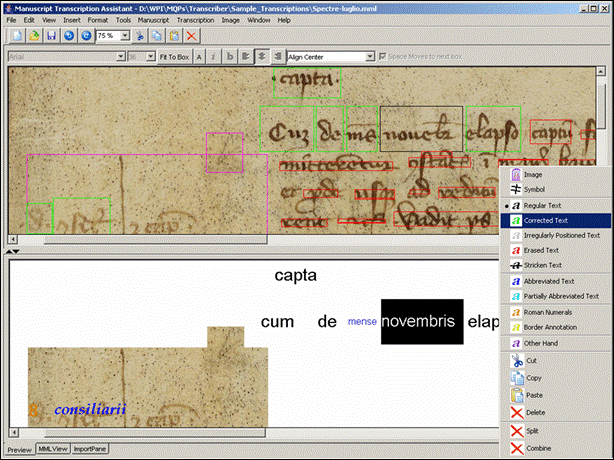 The TA is designed to greatly facilitate the process of
transcription. It consists of a main
screen split into two windows (vertically or horizontally, according to the
user’s preference). On one window is
loaded the manuscript image and on the other is visualized the transcription,
either as a positionally accurate print preview, or
as word-processable text, or in MML format (see tabs
at bottom left of Figure).
The TA is designed to greatly facilitate the process of
transcription. It consists of a main
screen split into two windows (vertically or horizontally, according to the
user’s preference). On one window is
loaded the manuscript image and on the other is visualized the transcription,
either as a positionally accurate print preview, or
as word-processable text, or in MML format (see tabs
at bottom left of Figure).
The first step the TA takes, as soon as a new XPG image
is loaded, is to automatically detect word boundaries in the manuscript image
and create boxes around each word. The “autoboxdraw” function uses a sophisticated smearing
algorithm, developed by one of our past projects [4]. The automatic boxing thresholds and settings
are user-adjustable to fit different document conditions. Boxing is quite successful in the current
version of the TA application, though a certain amount of manual adjustment is
expected to be always necessary.
Fortunately, the process of word-boxing needs to only be done once, so
the time expenditure is worth the effort.
We are currently working on making the manual act of box correction a rewardable, emergent feature of our system as well.
Once each word (or abbreviation) has been boxed, the user
can begin the actual process of transcription.
Un-transcribed boxes are red. The
current box (in black in Figure 1) can be clicked on, to reveal a text field
right above it where the transcription can be typed. To emulate the functions of a word processor,
the user can move to the next box by simply hitting the space bar in between
boxes. Once a transcription has been
typed in, its box will turn green and its translation will be entered into the
transcription MML and will appear in its exact relative location in the preview
window (below the image in Figure above).
The current version of TA allows the user to
“right-click” on a box to annotate the transcription. A primary form of annotation has to do with
differentiating graphics or symbols from text.
If a box is tagged as an “image” or “symbol” a cropped piece of the
manuscript will be copied into the preview window (and into the underlying MML)
as shown in Figure 1 (lower left of preview window). Currently we provide the
following other types of annotations for text boxes: (i)
manuscript annotations such as for stricken text or corrected text; (ii)
tagging of abbreviations; (iii) identification of numbers and (iv) identification
of handwriting changes (different author).
We foresee adding more of these annotations – such as the tagging of
currency and marginalia – as well as second-order tags to identify proper
names, names of places, professions, dates and the like.
The one-to-one pairing of
word-boxes-to-text-transcriptions is broken only by abbreviations, wherein a
single word box can be exploded into more than one transcription word. In any case, this pervasive one-to-one correspondence
allows the accrual of handwriting-recognition capabilities, which are planned
for future versions of the software. We
foresee that when users will experience difficulties in transcribing a specific
word, they will be able to ask for help by hitting a help key (such as F1).
Using the manuscript metadata for a bounded search –
limited to manuscripts that are likely to have the “same hand” – the system
will be able to pattern-match the handwriting in the box where the user is
having trouble, with a storehouse of boxes from previously completed
transcriptions from the same source, yielding transcription suggestions ranked
by their different levels of matching.
The user will thus be able to pick the suggestion that best fits the
sentence being transcribed. We foresee
making this advanced capability available “for a fee” in order to fuel our
incentive program. We want to entice
users to submit completed transcriptions in order to get the credit they need,
so they can later spend their banked credits to “buy” services like this “transcription
help”.
Once a transcription has been completed, the user can
save it and/or upload it back to the originating archive server for credit accounting. After several manuscripts have been worked
on, the user can also save the project and wrap things up for the day.
More
technical details about the TA will be provided in a forthcoming paper.
FABIO
CARRERA [Home,
Bio, News, Teaching, Research, Publications, Grants, Service, Contact]